이전 포스팅에서는 객체들의 책임이 올바르게 할당되지 않았던 문제를 다뤘습니다.
그러다 보니 거대한 몬스터 메서드들이 생겨났고, 이로 인해 유지보수와 확장이 어려웠었죠.
이 문제를 해소하기 위해 책임의 재할당을 다뤘었는데요, 이번 포스팅에서도 객체 지향 관점에서 책임의 재할당을 다룹니다.
책임의 재할당 과정에서 트랜잭션에서 외부 API 호출 로직을 분리하고, 데이터 주도 협력 관계에서 책임 주도 협력 관계로 나아가는 과정을 담았습니다.
의미 있는 타입으로 묶기
이전 포스팅에서 책임 재할당의 결과
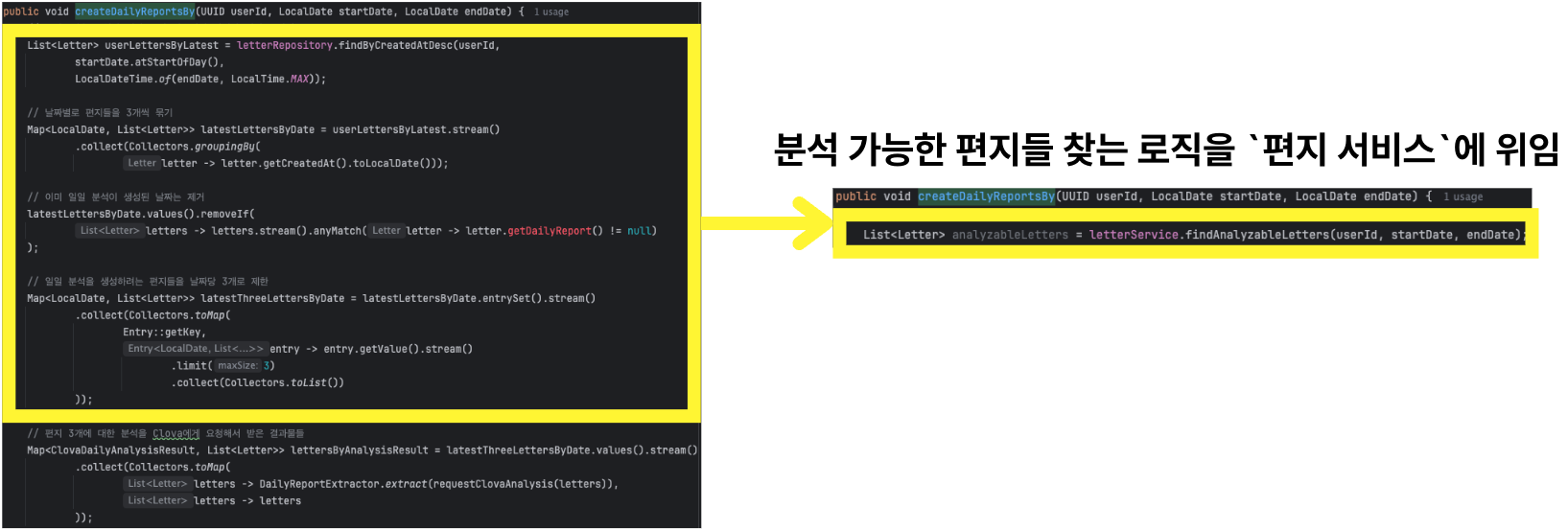
왼쪽은 `편지 서비스`가 해야 할 책임이 `데일리 리포트 서비스`에 있었던 부분입니다. (코드 20줄)
오른쪽은 `편지 서비스`에게 책임을 재할당하고, 해당 서비스에게 요청을 보내는 부분으로 개선된 코드입니다. (코드 1줄)
여기서 객체 지향으로 한 걸음 더 나아가 보겠습니다.
`편지 서비스`는 분석 가능한 편지들을 주어진 조건으로 찾고, 반환합니다.
이때, `분석 가능한 편지들`을 `List <Letter>` 타입으로 반환하는데요, 이 타입만으로는 의미가 분명하지 않습니다.
요점은 `List<Letter>` 타입만으로 `분석 가능한 편지들`을 `clovaService`를 이용해 생성형 AI에게 전달하고, 분석 결과를 받는다는 의미를 파악하기 어렵다는 것입니다.
그 이유는 `List<Letter>` 라는 타입으로 편지들이 리스트 형태로 있다는 것은 알지만, 데일리 리포트를 생성하기 위해 하루치만큼 그룹화가 되어있지 않기 때문입니다.
아래는 Stream API를 이용해 그룹화한 날짜 별 편지들입니다.
날짜 별 그룹화된 편지들(Map<LocalDate, List<Letter>)
Map<LocalDate, List<Letter>> analyzableLettersByDate = analyzableLetters.stream()
.collect(Collectors.groupingBy(letter -> letter.getCreatedAt().toLocalDate()));비로소 `Map<LocalDate, List<Letter>>` 타입이 되어서야 날짜 별로 묶인 편지들이라는 의미가 보이기 시작합니다.
하지만 이렇게 했음에도 value로 갖고 있는 `List<Letter>`들은 key가 없으면 `하루치 편지`라는 의미로 받아들이기가 어렵습니다.
따라서 아래와 같이 `하루치 편지`라는 의미를 갖도록 래퍼 클래스`(wrapper class)`를 작성했습니다.
DailyLetter
@NoArgsConstructor(access = AccessLevel.PRIVATE)
@AllArgsConstructor(access = AccessLevel.PRIVATE)
public class DailyLetters {
private static final String MERGE_FORMAT = "<%s:%s>\n%s\n</%s:%s>";
private static final String LETTER_SEPARATOR = "sharpie-sep";
private static final String ESCAPE_LT = "<";
private static final String ESCAPE_GT = ">";
private static final String ESCAPE_AMP = "&";
private static final String ESCAPE_QUOT = "\"";
private static final String ESCAPE_APOS = "'";
private List<Letter> letters;
public static DailyLetters from(List<Letter> letters) {
return new DailyLetters(letters);
}
public Letter getLetter(int naturalSequence) {
return letters.get(naturalSequence - 1);
}
public LocalDate getCreatedDate() {
return letters.stream()
.findAny()
.orElseThrow(() -> new LetterNotFoundException("편지가 존재하지 않아 날짜를 가져올 수 없습니다."))
.getCreatedAt()
.toLocalDate();
}
public String getMessages() {
String messageSeparator = Long.toHexString(Double.doubleToLongBits(Math.random()));
return letters.stream()
.map(letter -> String.format(MERGE_FORMAT,
LETTER_SEPARATOR, messageSeparator,
replaceEscapeCharacters(letter.getMessage()),
LETTER_SEPARATOR, messageSeparator))
.collect(Collectors.joining("\n"));
}
private String replaceEscapeCharacters(String message) {
return message
.replace(ESCAPE_LT, "<")
.replace(ESCAPE_GT, ">")
.replace(ESCAPE_AMP, "&")
.replace(ESCAPE_QUOT, """)
.replace(ESCAPE_APOS, "'");
}
}- 이 객체는 `하루치 편지들`을 의미합니다.
- 이 객체가 수신하는 메시지는 다음과 같습니다.
- `getLetter(int naturalIndex)`: 주어진 자연수 인덱스(1부터 시작)에 해당하는 편지를 가져옵니다.
(생성형 AI 응답에서 편지의 순서를 자연수로 주도록 설정했기 때문입니다.) - `getCreatedDate()`: `하루치`가 의미하는 해당 날짜를 의미합니다.
- `getMessages()`: `하루치 편지들`에서 편지 내용들을 모두 합친 메시지를 의미합니다.
생성형 AI에게 전달되며, 편지들을 구분하기 위해 내부에서 구분자가 사용되었습니다. - `replaceEscapeCharacters(String message)`: 편지 내용들 중 HTML escape 문자들을 치환하는 역할을 합니다.
- `getLetter(int naturalIndex)`: 주어진 자연수 인덱스(1부터 시작)에 해당하는 편지를 가져옵니다.
이제 위의 분석 가능한 편지들 `Map<LocalDate, List<Letter>`가 아니라 `List<DailyLetters>`로 반환하도록 편지 서비스 코드를 아래와 같이 수정했습니다.
LetterService 코드
@Transactional(readOnly = true)
public List<DailyLetters> findAnalyzableLetters(UUID userId, LocalDate startDate, LocalDate endDate) {
List<Letter> analyzableLetters = letterRepository.findAnalyzableLetters(userId, toStartDateTime(startDate),
toEndDateTime(endDate));
Map<LocalDate, List<Letter>> analyzableLettersByDate = analyzableLetters.stream()
.collect(Collectors.groupingBy(letter -> letter.getCreatedAt().toLocalDate()));
return analyzableLettersByDate.values().stream()
.map(DailyLetters::from)
.toList();
}이제 `분석 가능한 편지들`을 반환할 때 `List<DailyLetters>` 타입으로 반환하기 때문에 startDate와 endDate 사이에 존재하는 "하루치 편지들의 리스트"라는 의미가 됐습니다.
편지 분석(LetterAnalysis)의 책임
편지 분석(LetterAnalysis)은 편지 하나에 대해 감정 분석 관련 정보를 가장 많이 알고 있는 엔티티입니다.
이전 포스팅(도메인 모델을 리팩토링)에서 리팩토링한 결과로 `편지`와 `데일리 리포트`와 연관 관계를 아래 그림처럼 갖고 있습니다.

LetterAnalysis는 연관 관계의 주인으로, 연관된 편지와 데일리 리포트를 알고 있습니다.
우리 프로젝트는 DDD(Domain Driven Design)로 설계되진 않았지만, 엔티티 간 단방향 연관 관계는 모두 LetterAnalysis가 갖고 있습니다.

위의 그림은 프로젝트에서 생성형 AI가 편지들을 분석한 결과를 이용해 감정 분석(LetterAnalysis)과 데일리 리포트(DailyReport) 엔티티가 생성되는 흐름을 보여줍니다.
이를 종합하면, 편지 분석(LetterAnalysis) 엔티티의 책임은 아래로 정의할 수 있습니다.
편지 분석(LetterAnalysis)의 책임들
- `하루치 편지들(DailyLetters)`을 통해 감정 분석과 요약 정보를 생성할 책임이 있다.
- 단방향 연관 관계에서 데일리 리포트(DailyReport)는 단독으로 영속화될 수 없다.
따라서 편지 분석(LetterAnalysis)이 영속화(persist) 될 때 함께 영속화할 책임이 있다.
이제 전체 협력 관계 수준에서 정리하면 아래 그림과 같이 됩니다.
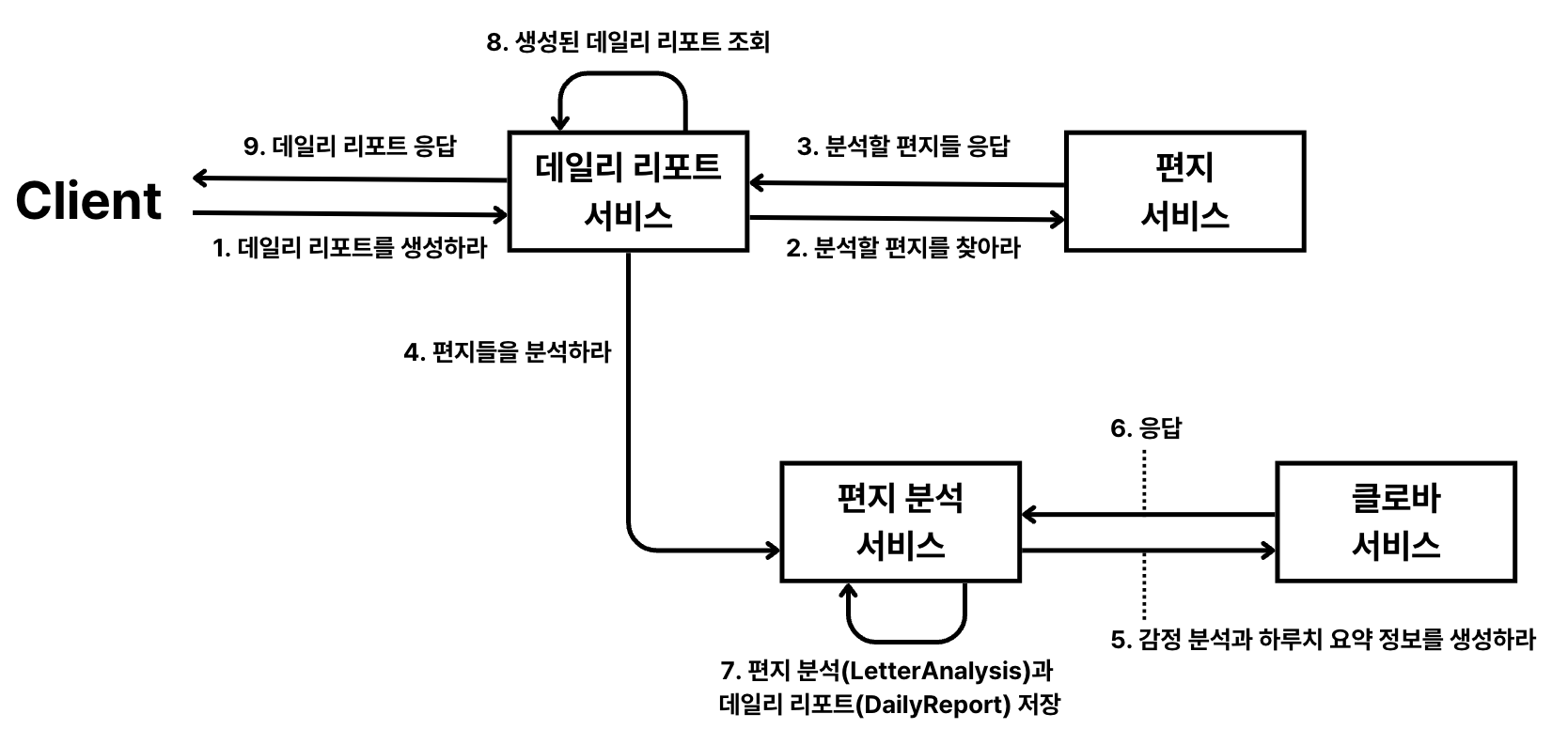
이를 바탕으로 `편지 분석 서비스(LetterAnalysisService)`는 "편지들을 분석하라"라는 메시지와 "편지 분석 결과와 데일리 리포트를 함께 저장하라"라는 메시지를 수신할 인터페이스가 필요한데요, 아래와 같이 구현했습니다.
LetterAnalysisService
@Service
@RequiredArgsConstructor
public class LetterAnalysisService {
private final ClovaService clovaService;
private final DailyReportPromptTemplate promptTemplate;
private final LetterAnalysisRepository letterAnalysisRepository;
/**
* '하루치 편지들'에 대한 감정 분석 생성 요청을 클로바 서비스에게 위입합니다.
*
* @param dailyLetters 분석에 사용될 하루치 편지들
* @return 편지들에 대한 분석 결과
*/
public DailyAnalysisResult createDailyAnalysis(DailyLetters dailyLetters) {
CreateResponse createResponse = clovaService.sendWithPromptTemplate(promptTemplate, dailyLetters.getMessages());
return DailyAnalysis.extract(createResponse);
}
/**
* 분석에 사용된 편지들과 그에 대응하는 분석 결과를 매핑하고, 데이터 액세스 계층에 저장을 위임합니다.
*
* @param dailyLetters 분석에 사용될 하루치 편지들
* @param dailyAnalysisResult 편지들에 대한 분석 결과
*/
@Transactional
public void saveAnalysisAndDailyReport(DailyLetters dailyLetters, DailyAnalysisResult dailyAnalysisResult) {
// 데일리 리포트 엔티티 생성
DailyReport dailyReport = DailyReport.builder()
.coreEmotion(dailyAnalysisResult.getDailyCoreEmotion())
.description(dailyAnalysisResult.getDescription())
.targetDate(dailyLetters.getCreatedDate())
.build();
// 감정 분석 추출
List<EmotionAnalysis> emotionAnalyses = dailyAnalysisResult.getEmotionAnalyses();
// 편지 분석 엔티티 (연관 관계 주인: cascade.PERSIST)
List<LetterAnalysis> letterAnalyses = emotionAnalyses.stream()
.map(emotionAnalysis -> LetterAnalysis.builder()
.letter(dailyLetters.getLetter(emotionAnalysis.getSequence()))
.dailyReport(dailyReport)
.topic(emotionAnalysis.getTopic())
.coreEmotions(emotionAnalysis.getCoreEmotions())
.sensitiveEmotions(emotionAnalysis.getSensitiveEmotions())
.build())
.toList();
letterAnalysisRepository.saveAll(letterAnalyses);
}
여기서 눈여겨봐야 할 부분은 외부 API를 호출하는 부분(`createDailyAnalysis()`)과 결과를 저장하는 부분(`saveAnalysisAndDailyReport()`)으로 나뉘었다는 것입니다.
외부 API를 분리하는 이유는 이 포스팅에서 설명한 적이 있는데요, 한 줄로 요약하면 외부 서비스의 장애가 우리 서비스까지 전파되기 때문입니다. 외부 서비스에서 장애가 발생하면 응답을 받기까지 지연이 될 수 있고, 지연에 길어지면 결국 커넥션 풀 고갈로 이어져 서비스 응답 불가를 초래할 수 있습니다.
아래 그림은 문제가 되는 외부 API 호출하는 부분을 트랜잭션에서 분리하기 위해서 `외부 API를 호출하는 부분`과 `결과를 저장하는 부분`을 나눈 것을 보여줍니다.

데일리 리포트 서비스의 책임
이제 편지들에 대한 감정 분석을 생성하고, 저장하는 책임은 `편지 분석 서비스(LetterAnalysisService)`에게 재할당 되었습니다.
이전 포스팅에 이어서 `위클리 리포트`를 생성하기 위한 `데일리 리포트를 사전 생성` 책임은 편지 분석 서비스에게 다시 메시지를 전달하도록 합니다.
AS-IS (TL;DR)
@Transactional
public void createDailyReportsBy(UUID userId, LocalDate startDate, LocalDate endDate) {
// 주간분석을 요청한 기간 동안 사용자가 작성한 편지들 찾기
List<Letter> userLettersByLatest = letterRepository.findByCreatedAtDesc(userId,
startDate.atStartOfDay(),
LocalDateTime.of(endDate, LocalTime.MAX));
// 날짜별로 편지들을 3개씩 묶기
Map<LocalDate, List<Letter>> latestLettersByDate = userLettersByLatest.stream()
.collect(Collectors.groupingBy(
letter -> letter.getCreatedAt().toLocalDate()));
// 이미 일일 분석이 생성된 날짜는 제거
latestLettersByDate.values().removeIf(
letters -> letters.stream().anyMatch(letter -> letter.getDailyReport() != null)
);
// 일일 분석을 생성하려는 편지들을 날짜당 3개로 제한
Map<LocalDate, List<Letter>> latestThreeLettersByDate = latestLettersByDate.entrySet().stream()
.collect(Collectors.toMap(
Entry::getKey,
entry -> entry.getValue().stream()
.limit(3)
.collect(Collectors.toList())
));
// 편지 3개에 대한 분석을 Clova에게 요청해서 받은 결과물들
Map<DailyAnalysisResult, List<Letter>> lettersByAnalysisResult = analyzableLettersByDate.values().stream()
.collect(Collectors.toMap(
letters -> DailyAnalysisExtractor.extract(requestClovaAnalysis(letters)),
letters -> letters
));
// 분석결과와 편지들을 가지고 데일리 리포트 생성
Map<DailyReport, List<Letter>> lettersByDailyReport = lettersByAnalysisResult.entrySet().stream()
.collect(Collectors.toMap(
entry -> buildDailyReport(entry.getValue().get(0).getCreatedAt().toLocalDate(), entry.getKey()),
Entry::getValue
));
dailyReportRepository.saveAll(lettersByDailyReport.keySet());
// 편지들에 알맞는 데일리 리포트를 setter 주입
lettersByDailyReport.forEach((key, value) ->
value.forEach(
letter -> letter.setDailyReport(key)
));
// 편지와 분석결과를 가지고 편지분석엔티티들 생성 및 저장
List<LetterAnalysis> letterAnalyses = lettersByAnalysisResult.entrySet().stream()
.flatMap(entry -> buildLetterAnalyses(entry.getValue(), entry.getKey()).stream())
.toList();
letterAnalysisRepository.saveAll(letterAnalyses);
}- 이전 코드는 `편지 저장소(letter repository)`를 데일리 리포트 서비스가 직접 제어합니다.
- `하루치 편지들`을 Stream API를 통해 직접 분류하며, 편지 분석(LetterAnalysis)과 데일리 리포트(DailyReport)의 영속화를 직접 다룹니다.
- `편지 저장소(letter repository)`, `편지 분석 저장소(letter analysis repository)`, `데일리 리포트 저장소(daily report repository)`와 강한 결합을 갖고 있습니다.
TO-BE
public void createDailyReportsBy(UUID userId, LocalDate startDate, LocalDate endDate) {
// 편지 서비스에게 `분석 가능한 편지들` 찾기 위임
List<DailyLetters> analyzableLetters = letterService.findAnalyzableLetters(userId, startDate, endDate);
for (DailyLetters dailyLetters : analyzableLetters) {
// 외부 API 호출
CreateResponse createResponse = clovaService.sendWithPromptTemplate(promptTemplate, dailyLetters.getMessages());
// 응답 결과로부터 하루치 분석 추출
DailyAnalysisResult analysisResult = DailyAnalysisExtractor.extract(createResponse);
// 트랜잭션 안에서 하루치 분석으로부터 편지 분석, 데일리 리포트 엔티티 저장
letterAnalysisService.saveAnalysisAndDailyReport(dailyLetters, analysisResult);
}
}
- "묻지 말고 시켜라"를 적용한 코드입니다.
데일리 리포트 서비스의 책임을 벗어나는 메시지는 적절한 객체에게 다시 위임되는 구조가 되었습니다. - 책임의 재할당으로 인해 `편지 저장소`, `편지 분석 저장소`, `데일리 리포트 저장소`와의 강한 결합이 제거되었습니다.
- 이제 편지 분석과 데일리 리포트 생성의 책임은 `편지 분석 서비스`에게 할당되었기 때문에 생성과 저장에 있어서 변경 사항이 `데일리 리포트 서비스`까지 전파되지 않습니다.
- 간략해진 코드로 유지보수가 쉬워졌습니다.
추가 문제 (동기적인 외부 API 호출)
아직 해결되지 않은 문제가 있습니다.
바로 반복문(for loop) 안에서 외부 API를 호출하는 부분인데요,
프로젝트는 FeignClient를 통해 동기적으로 HTTP 요청을 보냅니다.
요청으로부터 응답은 평균 7초 정도인데, 7일 치 편지 묶음을 보내면 응답을 받기까지 1분이 넘게 걸리는 문제가 있습니다.

이는 사용자의 서비스 경험을 저해하는 요소이며, 사용 중인 nginx ingress의 리드 타임이 60초로 되어있어 커넥션이 끊어지지 않도록 인프라 설정까지 수정해야 했습니다.
다음 포스팅에선 동기적인 HTTP 요청을 비동기적으로 보내 이 문제를 해결하는 과정을 다룹니다.
마치며
이전 포스팅에 이어 책임 재할당을 주제로 리팩토링을 진행하며, 데이터 주도 설계에서 책임 주도 설계로 나아가는 과정에서 "묻지 말고 시켜라" 원칙을 적용해 봤습니다.
`하루치 편지들(DailyLetters)`이라는 타입을 정의하고, 각 객체에게 책임을 재할당해 메시지 처리를 위임하는 방식으로 코드를 개선했습니다. 또한, 트랜잭션과 외부 API 호출을 분리하여 코드의 안정성과 유지보수성을 높이는 작업도 진행했습니다.
그 결과 가독성과 유지보수성을 향상한 코드를 얻을 수 있어 만족스러웠습니다.
아래는 간단하게 정리한 이번 리팩토링에서 얻은 몇 가지 교훈입니다.
- 책임 주도 설계는 코드의 응집도를 높이고 결합도를 낮춰준다.
- "묻지 말고 시켜라" 원칙은 객체 간의 협력을 증진시키고 코드의 유연성을 높여준다.
- 트랜잭션과 외부 API 호출을 분리하면 코드의 안정성과 유지보수성을 향상할 수 있다.
이 글을 읽는 분들도 자신의 코드에 책임 주도 설계와 "묻지 말고 시켜라" 원칙을 적용하여 코드의 품질을 향상하는 경험을 해 보시면 좋을 것 같습니다.
다음 포스팅에선 동기적으로 요청하는 외부 API 호출을 비동기로 바꾸는 과정을 다룹니다. 관심 있으시다면 추가되는 링크를 참고해 주세요!
긴 글 읽어주셔서 감사합니다.
'Project' 카테고리의 다른 글
| 프로젝트 리팩토링 (5) - HTTP 요청 비동기 처리 (0) | 2025.02.07 |
|---|---|
| 프로젝트 리팩토링 (3) - 책임 재할당과 실행 계획 분석으로 검증하기 (1) | 2025.02.04 |
| 프로젝트 리팩토링 (2) - 도메인 모델 리팩토링 (0) | 2025.02.02 |
| 프로젝트 리팩토링 (1) - 객체 지향 설계 (1) | 2025.01.31 |
| 모놀리식 아키텍처에서 이벤트 기반으로 비즈니스 로직의 원자성 확보하기 (2) (1) | 2025.01.17 |